Hello!
Today, we’ll be talking about LSTM Networks QnA Style. The motivation for this is again as I have seen often when people read about LSTM’s, they have more questions than they have answers for. So, here I will try to give a gist of LSTM networks in comparison to FFN(Feed Forward Network or a regular NN).
So, Lets begin.
Q. How is LSTM different from a FFN cell(or a Feed Forward Network cell or a Node in hidden layer w.r.t. FFN)?
>The fundamental difference between a LSTM Cell and a FFN cell is that the LSTM cell itself is a combination of 4 networks. Yes, you read that right!
Q. Why do we have 4 networks in a single cell?
>Because we need memory or ‘previous state information’. And one way of achieving that is the implemented Networks.
Q. What are these 4 networks?
>We’l go into the details shortly. Refer to section: ‘The Worthy Networks!’
Q. Why do we need ‘previous state information’?
>Because we don’t want to loose context, and we believe that knowing the context could help better predict/classify the target.
Q. What if you are wrong, in the sense, previous state information is not required?
>Well, we could be. Generally, in applications where ‘sequence’ is of importance, LSTM’s do well. They essentially capture the sequence information(previous state) in the ‘memory’ cells.
Q. Wait, you said Sequence. CNN’s(Convolutional Neural Networks) are good with sequences. I could get away by using CNN and not use LSTM?
>Again, you could, depending on you application. One could say that there is a similarity between these two work as opposed to a FFN. They both take sequence(batch) of inputs. But that is where the similarity ends
Once the data is in the hidden layers, for a CNN, the hidden state of the first image window(batch) will not be supplied to next image window; for a LSTM, this will be the case. I know this looks short, but this topic deserves an article on its own; I’ll try to come up with one soon.
Q. Okay, so you say that a single LSTM cell is a cell with 4 networks, then for a hidden layer in LSTM implementation, do I have multiple LSTM cells?
>Well, Let me put it this way. A single LSTM cell is equivalent to a hidden layer in FFN. Again, that IS true. Similar to what you have number of nodes in a hidden layer, LSTM cell takes the number of hidden nodes as a parameter. This is the number of nodes in each of these 4 layers. As far as stacking goes, you can stack multiple LSTM cells, which will be similar to stacking of hidden layers when compared to FFN.
Okay, Let’s take a stab at the working of LSTM. The cell has following components.
- Long Term Memory,
- Short Term Memory,
- Input

The above diagram is read from left to right, bottom to top. So, as in case of FFN, you take input and predict output. Also, you use short term memory and long term memory to make a prediction. Also, we need to update the respective memories.
The Worthy Networks!
- The Learn Network.
- The Forget Network
- The Remember Network.
- The Use Network.
Lets take a look at each network in a bit detail.
- Learn Network: This network combines the Event Data and the Short term memory, learns new information from the event, and forgets what is not required.
- Forget Network: The long term memory goes here and forgets what is not required. It needs the Short term memory as well to identify what is not required.
- Remember Network: We combine the Long term memory and short term memory to get the updated Long term memory
- Use Network: As the name suggests, it takes into account, whatever we already know (long term memory) and whatever we learnt recently(short term memory), and combine them to predict the output. The output becomes the new short term memory and prediction.
Learn Network:
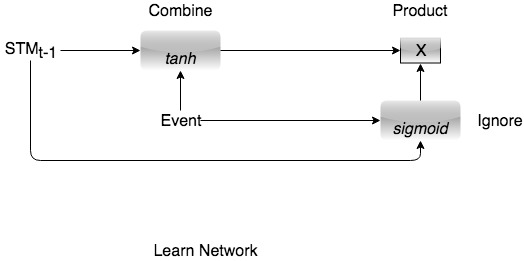
There is nothing to worry about.
We had 2 operations, Combine and Ignore for Short Term memory. And we are doing nothing more here.
Why tanh for Combine, and sigmoid for Ignore? Because, it works! I am sorry here. If someone has a better understanding, please share. The documents I found had empirical conclusions, and not something that I could derive intuition from.
Forget Network.
Here, for Long Term memory, we need to forget what is not required. So, we multiply LTM by a forget factor. How do we get forget factor? Another network to rescue!.

Remember Network
Here, we update the long term memory. How do we do it? Combine Long Term (whatever is important) with Short Term(updated with latest event data).
The Learn Network and Forget Network have exactly what we need. So we just add them.

Use Network
Here, we take what is useful from Long term memory(Forget Network); take the most recent Short Term memory, combine, and that is going to be our new short term memory.

One catch here is the tanh function. If we only wanted the updated LTM, we could just have used output of forget network directly. Empirically, the tanh is proved to be improving performance of networks under test. Again, here, if someone has a better understanding, please share inputs, and I will update the article to be more intuitive.
THE MOMENT OF TRUTH!
Putting it all together:

This is the famous LSTM Cell. Now if you plugin the individual networks in the respective cells, you should see the scary LSTM cell, that one generally sees. It should not look scary now. Try that as an exercise. It is actually fun.
Thats it guys.
Cheers. Happy Learning

Nice short tutorial, thanks! I would like to see this in code, with keras for example 🙂
Thanks a lot.
LikeLiked by 1 person
Sure thing. I wanted to add code here, but it was already too long. Also, one would not see the gates in keras/tensor flow, you would only have code blocks on the lines of
#for a basic lstm cell, as described above
lstm= tf.contrib.rnn.BasicLSTMCell(lstm_size)
#for dropout
drop=tf.contrib.rnn.DropoutWrapper(lstm,keep_prob)
#Stack up multiple LSTM layers
cell= tf.contrib.rnn.MultiRNNCell([drop] * num_layers)
LikeLiked by 1 person